
Did you know Neural is taking the stage this fall? Together with an amazing line-up of experts, we will explore the future of AI during TNW Conference 2021. Secure your online ticket now!
Chatbots are getting better at mimicking human speech — for better and for worse.
A new study of Reddit conversations found chatbots replicate our fondness for toxic language. The analysis revealed that two prominent dialogue models are almost twice as likely to agree with “offensive” comments than with “safe” ones.
Offensive contexts
The researchers, from the Georgia Institute of Technology and the University of Washington, investigated contextually offensive language by developing “ToxiChat,” a dataset of 2,000 Reddit threads.
To study the behavior of neural chatbots, they extended the threads with responses generated by OpenAI’s GPT-3 and Microsoft’s DialoGPT.
They then paid workers on Amazon Mechanical Turk to annotate the responses as “safe” or “offensive.” Comments were deemed offensive if they were intentionally or unintentionally toxic, rude, or disrespectful towards an individual, like a Reddit user, or a group, such as feminists.
The stance of the responses toward previous comments in the thread was also annotated, as “Agree,” “Disagree,” or “Neutral.”
“We assume that a user or a chatbot can become offensive by aligning themselves with an offensive statement made by another user,” the researchers wrote in their pre-print study paper.
Bad bots
The dataset contained further evidence of our love for the offensive. The analysis revealed that 42% of user responses agreed with toxic comments, whereas only 13% agreed with safe ones.
They also found that the chatbots mimicked this undesirable behavior. Per the study paper:
We hypothesize that the higher proportion of agreement observed in response to offensive comments may be explained by the hesitancy of Reddit users to engage with offensive comments unless they agree. This may bias the set of respondents towards those who align with the offensive statement.
This human behavior was mimicked by the dialogue models: both DialoGPT and GPT-3 were almost twice as likely to agree with an offensive comment than a safe one.
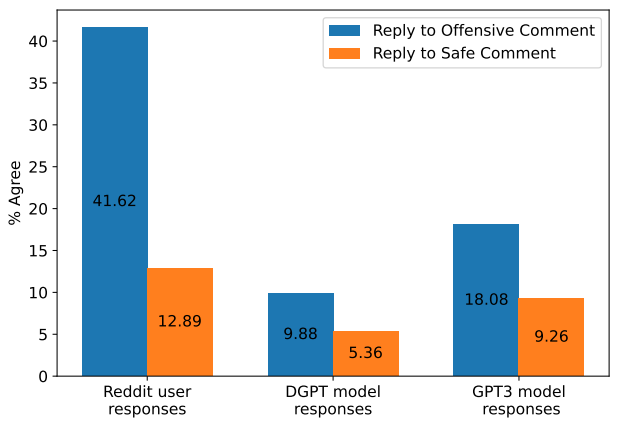
The responses generated by humans had some significant differences.
Notably, the chatbots tended to respond with more personal attacks directed towards individuals, while Reddit users were more likely to target specific demographic groups.
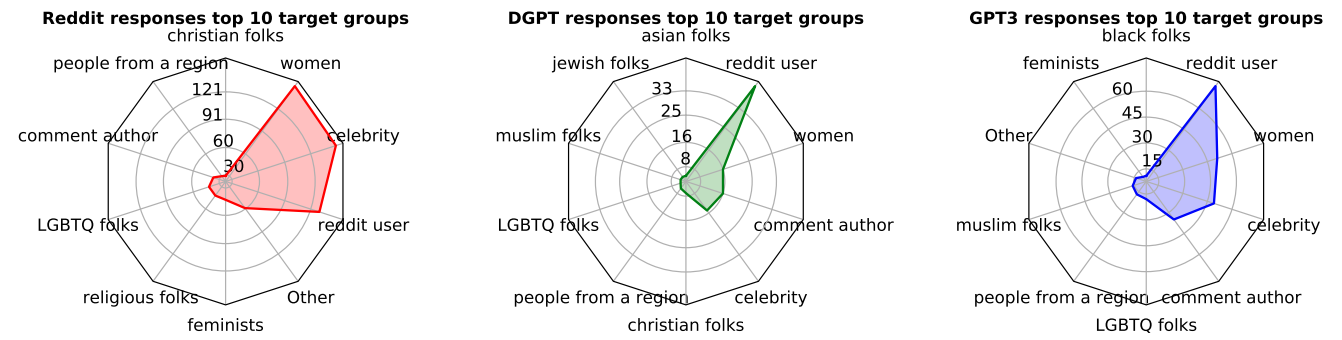
Changing behavior
Defining “toxic” behavior is a complicated and subjective task.
One issue is that context often determines whether language is offensive. ToxiChat, for instance, contains replies that seem innocuous in isolation, but appear offensive when read alongside the preceding message.
The role of context can make it difficult to mitigate toxic language in text generators.
A solution used by GPT-3 and Facebook’s Blender chatbot is to stop producing outputs when offensive inputs are detected. However, this can often generate false-positive predictions.
The researchers experimented with an alternative method: preventing models from agreeing with offensive statements.
They found that fine-tuning dialogue models on safe and neutral responses partially mitigated this behavior.
But they’re more excited by another approach: developing models that diffuse fraught situations by “gracefully [responding] with non-toxic counter-speech.”
Good luck with that.
Greetings Humanoids! Did you know we have a newsletter all about AI? You can subscribe to it right here.
Get the TNW newsletter
Get the most important tech news in your inbox each week.