
Move over GPT-3, there’s a scrappy new contender for the crown of world’s greatest language model and it’s from our old pals over at DeepMind.
Up front: The Alphabet-owned UK outfit that answered the question of whether humans or computers are better at chess once and for all – the machines won – has now set its sights on the world of large language models (LLM).
To that end, today it announced “Gopher,” a language model that’s about 60% larger, parameter-wise, than GPT-3 and a little over a quarter of the size of Google’s massive trillion-parameter LLM.
Per a press release on the DeepMind blog:
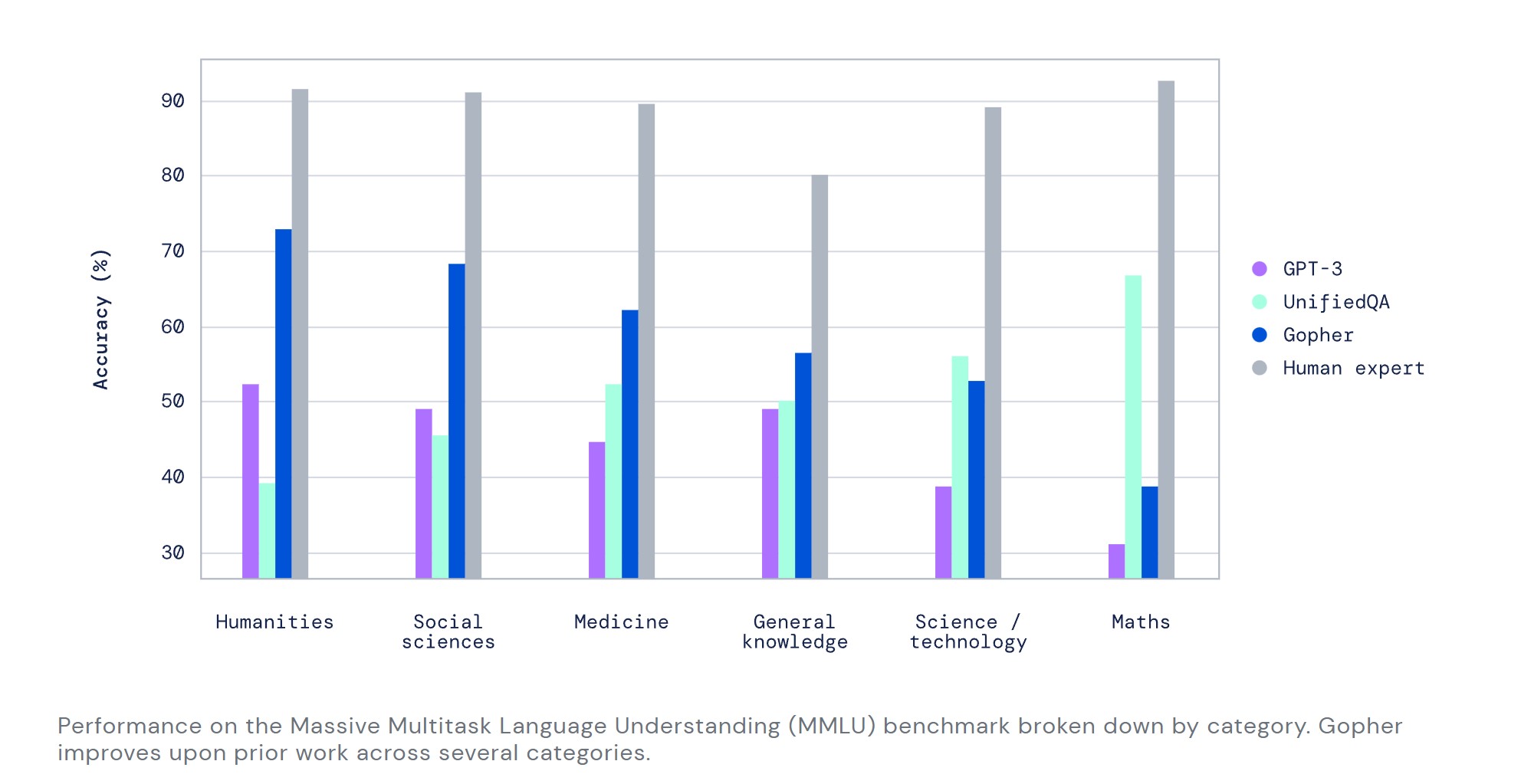
In our research, we found the capabilities of Gopher exceed existing language models for a number of key tasks. This includes the Massive Multitask Language Understanding (MMLU) benchmark, where Gopher demonstrates a significant advancement towards human expert performance over prior work.

The 💜 of EU tech
The latest rumblings from the EU tech scene, a story from our wise ol' founder Boris, and some questionable AI art. It's free, every week, in your inbox. Sign up now!
Background: DeepMind accomplished the improvements by focusing in on areas where expanding the size of an AI model made sense.
The more power you can shove into a model for, say, reading comprehension, the better. But the team found that other areas of LLM architecture didn’t benefit as much from brute force.
By prioritizing how the system utilizes and distributes resources, the team was able to tweak their algorithms to outperform state-of-the-art models in 80% of the benchmarks used.
The DeepMind team also released papers discussing the ethics and architecture of LLMs, you can read those here and here.
Quick take: To paraphrase the great poet Montell Jordan: this is how you do it. Instead of careening the field towards ruin by increasing the size of models exponentially until GPT-5 or GPT-6 ends up being larger than the known universe, DeepMind’s trying to squeeze more oomph out of smaller models.
Don’t get me wrong, Gopher has significantly more parameters than GPT-3. But, when you consider that GPT-4 is expected to have about 100 trillion parameters, it looks like DeepMind’s moving in a more feasible direction.
Get the TNW newsletter
Get the most important tech news in your inbox each week.