
Did you know Neural is taking the stage this fall? Together with an amazing line-up of experts, we will explore the future of AI during TNW Conference 2021. Secure your ticket now!
There’s growing concern about new security threats that arise from machine learning models becoming an important component of many critical applications. At the top of the list of threats are adversarial attacks, data samples that have been inconspicuously modified to manipulate the behavior of the targeted machine learning model.
Adversarial machine learning has become a hot area of research and the topic of talks and workshops at artificial intelligence conferences. Scientists are regularly finding new ways to attack and defend machine learning models.
A new technique developed by researchers at Carnegie Mellon University and the KAIST Cybersecurity Research Center employs unsupervised learning to address some of the challenges of current methods used to detect adversarial attacks. Presented at the Adversarial Machine Learning Workshop (AdvML) of the ACM Conference on Knowledge Discovery and Data Mining (KDD 2021), the new technique takes advantage of machine learning explainability methods to find out which input data might have gone through adversarial perturbation.
Creating adversarial examples
Say an attacker wants to stage an adversarial attack that causes an image classifier to change the label of an image from “dog” to “cat.” The attacker starts with the unmodified image of a dog. When the target model processes this image, it returns a list of confidence scores for each of the classes it has been trained on. The class with the highest confidence score corresponds to the class to which the image belongs.

The attacker then adds a small amount of random noise to the image and runs it through the model again. The modification results in a small change to the model’s output. By repeating the process, the attacker finds a direction that will cause the main confidence score to decrease and the target confidence score to increase. By repeating this process, the attacker can cause the machine learning model to change its output from one class to another.
Adversarial attack algorithms usually have an epsilon parameter that limits the amount of change allowed to the original image. The epsilon parameter makes sure the adversarial perturbations remain imperceptible to human eyes.

There are different ways to defend machine learning models against adversarial attacks. However, most popular defense methods introduce considerable costs in computation, accuracy, or generalizability.
For example, some methods rely on supervised adversarial training. In such cases, the defender must generate a large batch of adversarial examples and fine-tune the target network to correctly classify the modified examples. This method incurs example-generation and training costs, and in some cases, it might degrade the performance of the target model on the original task. It also isn’t guaranteed to work against attack techniques that it hasn’t been trained for.
Other defense methods require the defenders to train a separate machine learning model to detect specific types of adversarial attacks. This might help preserve the accuracy of the target model, but it is not guaranteed to work against unknown adversarial attack techniques.
Adversarial attacks and explainability in machine learning
In their research, the scientists from CMU and KAIST found a link between adversarial attacks and explainability, another key challenge of machine learning. In many machine learning models—especially deep neural networks—decisions are hard to trace due to the large number of parameters involved in the inference process.
This makes it difficult to employ these algorithms in applications where the explanation of algorithmic decisions is a requirement.
To overcome this challenge, scientists have developed different methods that can help understand the decisions made by machine learning models. One range of popular explainability techniques produces saliency maps, where each of the features of the input data are scored based on their contribution to the final output.
For example, in an image classifier, a saliency map will rate each pixel based on the contribution it makes to the machine learning model’s output.
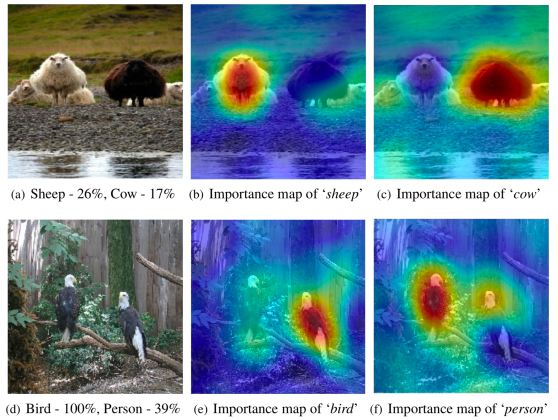
The intuition behind the new method developed by Carnegie Mellon University is that when an image is modified with adversarial perturbations, running it through an explainability algorithm will produce abnormal results.
“Our recent work began with a simple observation that adding small noise to inputs resulted in a huge difference in their explanations,” Gihyuk Ko, Ph.D. Candidate at Carnegie Mellon and lead author of the paper, told TechTalks.
Unsupervised detection of adversarial examples
The technique developed by Ko and his colleagues detects adversarial examples based on their explanation maps.
The development of the defense takes place in multiple steps. First, an “inspector network” uses explainability techniques to generate saliency maps for the data examples used to train the original machine learning model.
Next, the inspector uses the saliency maps to train “reconstructor networks” that recreate the explanations of each decision made by the target model. There are as many reconstructor networks as there are output classes in the target model. For instance, if the model is a classifier for handwritten digits, it will need ten reconstructor networks, one for each digit. Each reconstructor is an autoencoder network. It takes an image as input and produces its explanation map. For example, if the target network classifies an input image as a “4,” then the image is run through the reconstructor network for the class “4,” which produces the saliency map for that input.
Since the constructor networks are trained on benign examples, when they are provided with adversarial examples, their output will be very unusual. This allows the inspector to detect and flag adversarially perturbed images.
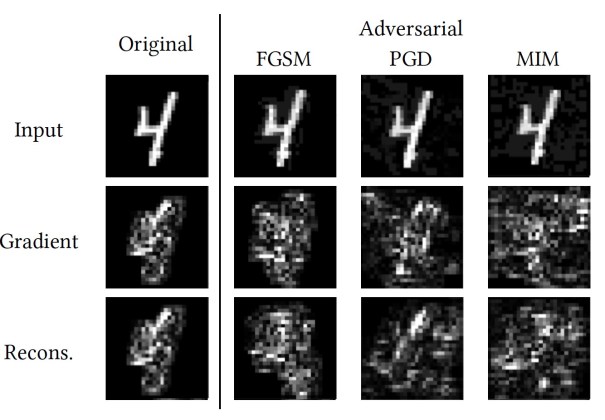
Experiments by the researchers show that abnormal explanation maps are common across all adversarial attack techniques. Therefore, the main benefit of this method is that it is attack-agnostic and doesn’t need to be trained on specific adversarial techniques.
“Prior to our method, there have been suggestions in using SHAP signatures to detect adversarial examples,” Ko said. “However, all the existing works were computationally costly, as they relied on pre-generation of adversarial examples to separate SHAP signatures of normal examples from adversarial examples. In contrast, our unsupervised method is computationally better as no pre-generated adversarial examples are needed. Also, our method can be generalized to unknown attacks (i.e., attacks that were not previously trained).”
The scientists tested the method on MNIST, a dataset of handwritten digits often used in testing different machine learning techniques. According to their findings, the unsupervised detection method was able to detect various adversarial attacks with performance that was on par or better than known methods.
“While MNIST is a fairly simple dataset to test methods, we think our method will be applicable to other complicated datasets as well,” Ko said, though he also acknowledged that it is much more difficult to detect the difference between benign and adversarial examples for complex deep learning models trained on real-world datasets.
In the future, the researchers will test the method on more complex datasets, such as CIFAR10/100 and ImageNet, and more complicated adversarial attacks.
“In the perspective of using model explanations to secure deep learning models, I think that model explanations can play an important role in repairing vulnerable deep neural networks,” Ko said.
This article was originally published by Ben Dickson on TechTalks, a publication that examines trends in technology, how they affect the way we live and do business, and the problems they solve. But we also discuss the evil side of technology, the darker implications of new tech, and what we need to look out for. You can read the original article here.
Get the TNW newsletter
Get the most important tech news in your inbox each week.