Machine learning has become an important component of many applications we use today. And adding machine learning capabilities to applications is becoming increasingly easy. Many ML libraries and online services don’t even require a thorough knowledge of machine learning.
However, even easy-to-use machine learning systems come with their own challenges. Among them is the threat of adversarial attacks, which has become one of the important concerns of ML applications.
Adversarial attacks are different from other types of security threats that programmers are used to dealing with. Therefore, the first step to countering them is to understand the different types of adversarial attacks and the weak spots of the machine learning pipeline.
In this post, I will try to provide a zoomed-out view of the adversarial attack and defense landscape with help from a video by Pin-Yu Chen, AI researcher at IBM. Hopefully, this can help programmers and product managers who don’t have a technical background in machine learning get a better grasp of how they can spot threats and protect their ML-powered applications.
1: Know the difference between software bugs and adversarial attacks
Software bugs are well-known among developers, and we have plenty of tools to find and fix them. Static and dynamic analysis tools find security bugs. Compilers can find and flag deprecated and potentially harmful code use. Test units can make sure functions respond to different kinds of input. Anti-malware and other endpoint solutions can find and block malicious programs and scripts in the browser and the computer hard drive.

The 💜 of EU tech
The latest rumblings from the EU tech scene, a story from our wise ol' founder Boris, and some questionable AI art. It's free, every week, in your inbox. Sign up now!
Web application firewalls can scan and block harmful requests to web servers, such as SQL injection commands and some types of DDoS attacks. Code and app hosting platforms such as GitHub, Google Play, and Apple App Store have plenty of behind-the-scenes processes and tools that vet applications for security.
In a nutshell, although imperfect, the traditional cybersecurity landscape has matured to deal with different threats.
But the nature of attacks against machine learning and deep learning systems is different from other cyber threats. Adversarial attacks bank on the complexity of deep neural networks and their statistical nature to find ways to exploit them and modify their behavior. You can’t detect adversarial vulnerabilities with the classic tools used to harden software against cyber threats.
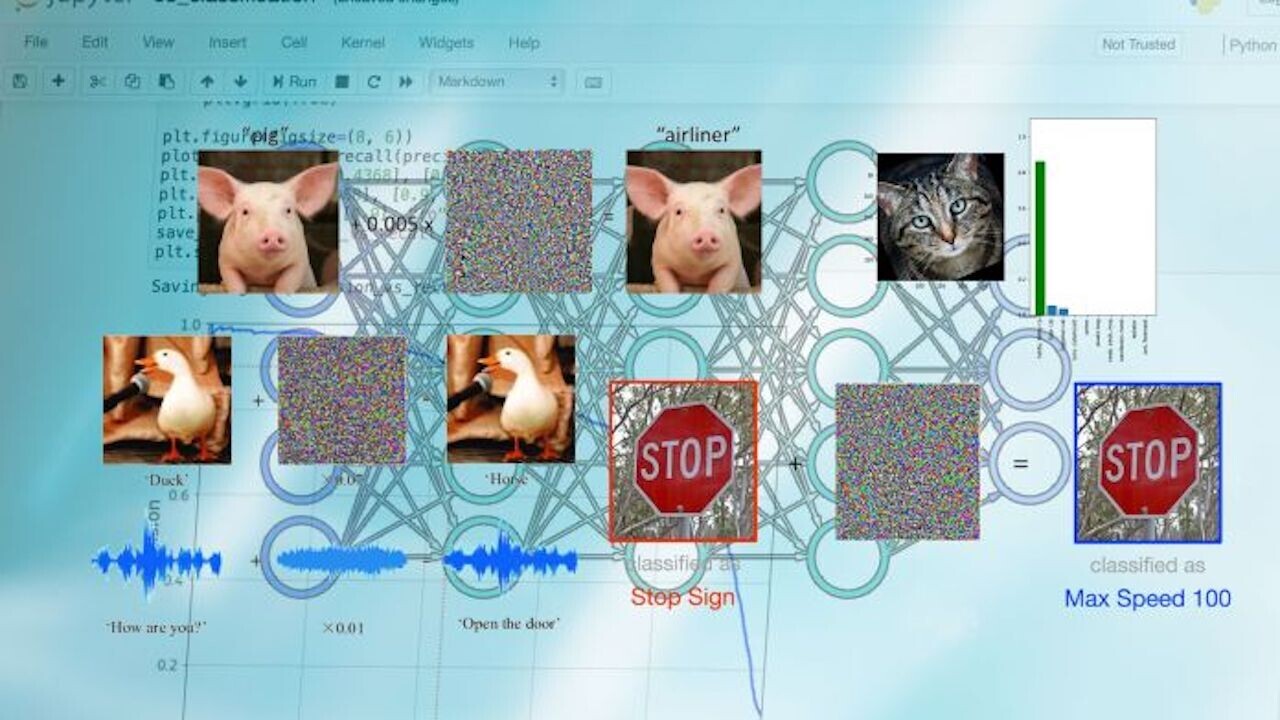
In recent years, adversarial examples have caught the attention of tech and business reporters. You’ve probably seen some of the many articles that show how machine learning models mislabel images that have been manipulated in ways that are imperceptible to the human eye.

While most examples show attacks against image classification machine learning systems, other types of media can also be manipulated with adversarial examples, including text and audio.
“It is a kind of universal risk and concern when we are talking about deep learning technology in general,” Chen says.
One misconception about adversarial attacks is that it affects ML models that perform poorly on their main tasks. But experiments by Chen and his colleagues show that, in general, models that perform their tasks more accurately are less robust against adversarial attacks.
“One trend we observe is that more accurate models seem to be more sensitive to adversarial perturbations, and that creates an undesirable tradeoff between accuracy and robustness,” he says.
Ideally, we want our models to be both accurate and robust against adversarial attacks.

2: Know the impact of adversarial attacks
In adversarial attacks, context matters. With deep learning capable of performing complicated tasks in computer vision and other fields, they are slowly finding their way into sensitive domains such as healthcare, finance, and autonomous driving.
But adversarial attacks show that the decision-making process of deep learning and humans are fundamentally different.
In safety-critical domains, adversarial attacks can cause risk to the life and health of the people who will be directly or indirectly using the machine learning models. In areas like finance and recruitment, it can deprive people of their rights and cause reputational damage to the company that runs the models. In security systems, attackers can game the models to bypass facial recognition and other ML-based authentication systems.
Overall, adversarial attacks cause a trust problem with machine learning algorithms, especially deep neural networks. Many organizations are reluctant to use them due to the unpredictable nature of the errors and attacks that can happen.
If you’re planning to use any sort of machine learning, think about the impact that adversarial attacks can have on the function and decisions that your application makes. In some cases, using a lower-performing but predictable ML model might be better than one that can be manipulated by adversarial attacks.
3: Know the threats to ML models
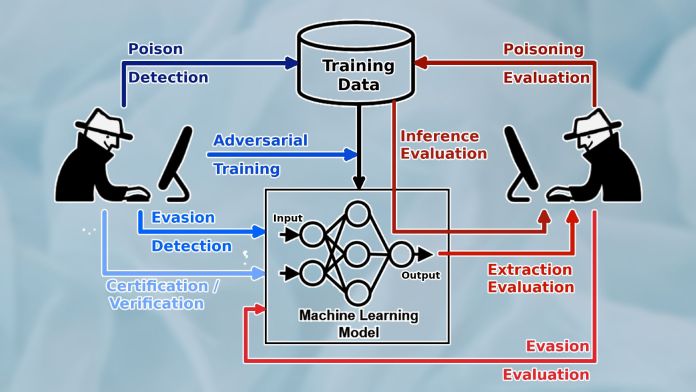
The term adversarial attack is often used loosely to refer to different types of malicious activity against machine learning models. But adversarial attacks differ based on what part of the machine learning pipeline they target and the kind of activity they involve.
Basically, we can divide the machine learning pipeline into the “training phase” and “test phase.” During the training phase, the ML team gathers data, selects an ML architecture, and trains a model. In the test phase, the trained model is evaluated on examples it hasn’t seen before. If it performs on par with the desired criteria, then it is deployed for production.
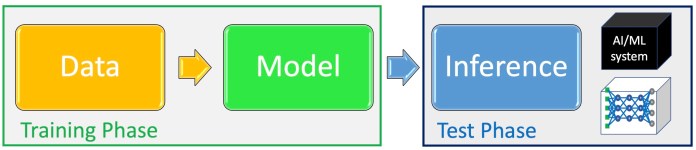
Adversarial attacks that are unique to the training phase include data poisoning and backdoors. In data poisoning attacks, the attacker inserts manipulated data into the training dataset. During training, the model tunes its parameters on the poisoned data and becomes sensitive to the adversarial perturbations they contain. A poisoned model will have erratic behavior at inference time. Backdoor attacks are a special type of data poisoning, in which the adversary implants visual patterns in the training data. After training, the attacker uses those patterns during inference time to trigger specific behavior in the target ML model.
Test phase or “inference time” attacks are the types of attacks that target the model after training. The most popular type is “model evasion,” which is the typical adversarial example that has become popular. An attacker creates an adversarial example by starting with a normal input (e.g., an image) and gradually adding noise to it to skew the target model’s output toward the desired outcome (e.g., a specific output class or general loss of confidence).
Another class of inference-time attacks tries to extract sensitive information from the target model. For example, membership inference attacks use different methods to trick the target ML model to reveal its training data. If the training data included sensitive information such as credit card numbers or passwords, these types of attacks can be very damaging.

Another important factor in machine learning security is model visibility. When you use a machine learning model that is published online, say on GitHub, you’re using a “white box” model. Everyone else can see the model’s architecture and parameters, including attackers. Having direct access to the model will make it easier for the attacker to create adversarial examples.
When your machine learning model is accessed through an online API such as Amazon Recognition, Google Cloud Vision, or some other server, you’re using a “black box” model. Black-box ML is harder to attack because the attacker only has access to the output of the model. But harder doesn’t mean impossible. It is worth noting there are several model-agnostic adversarial attacks that apply to black-box ML models.
4: Know what to look for
What does this all mean for you as a developer or product manager? “Adversarial robustness for machine learning really differentiates itself from traditional security problems,” Chen says.
The security community is gradually developing tools to build more robust ML models. But there’s still a lot of work to be done. And for the moment, your due diligence will be a very important factor in protecting your ML-powered applications against adversarial attacks.
Here are a few questions you should ask when considering using machine learning models in your applications:
Where does the training data come from? Images, audio, and text files might seem innocuous per se. But they can hide malicious patterns that can poison the deep learning model that will be trained by them. If you’re using a public dataset, make sure the data comes from a reliable source, possibly vetted by a known company or an academic institution. Datasets that have been referenced and used in several research projects and applied machine learning programs have higher integrity than datasets with unknown histories.
What kind of data are you training your model on? If you’re using your own data to train your machine learning model, does it include sensitive information? Even if you’re not making the training data public, membership inference attacks might enable attackers to uncover your model’s secrets. Therefore, even if you’re the sole owner of the training data, you should take extra measures to anonymize the training data and protect the information against potential attacks on the model.
Who is the model’s developer? The difference between a harmless deep learning model and a malicious one is not in the source code but in the millions of numerical parameters they comprise. Therefore, traditional security tools can’t tell you whether if a model has been poisoned or if it is vulnerable to adversarial attacks.
So, don’t just download some random ML model from GitHub or PyTorch Hub and integrate it into your application. Check the integrity of the model’s publisher. For instance, if it comes from a renowned research lab or a company that has skin in the game, then there’s little chance that the model has been intentionally poisoned or adversarially compromised (though the model might still have unintentional adversarial vulnerabilities).
Who else has access to the model? If you’re using an open-source and publicly available ML model in your application, then you must assume that potential attackers have access to the same model. They can deploy it on their own machine and test it for adversarial vulnerabilities, and launch adversarial attacks on any other application that uses the same model out of the box.
Even if you’re using a commercial API, you must consider that attackers can use the exact same API to develop an adversarial model (though the costs are higher than white-box models). You must set your defenses to account for such malicious behavior. Sometimes, adding simple measures such as running input images through multiple scaling and encoding steps can have a great impact on neutralizing potential adversarial perturbations.
Who has access to your pipeline? If you’re deploying your own server to run machine learning inferences, take great care to protect your pipeline. Make sure your training data and model backend are only accessible by people who are involved in the development process. If you’re using training data from external sources (e.g., user-provided images, comments, reviews, etc.), establish processes to prevent malicious data from entering the training/deployment process. Just as you sanitize user data in web applications, you should also sanitize data that goes into the retraining of your model.
As I’ve mentioned before, detecting adversarial tampering on data and model parameters is very difficult. Therefore, you must make sure to detect changes to your data and model. If you’re regularly updating and retraining your models, use a versioning system to roll back the model to a previous state if you find out that it has been compromised.
5: Know the tools

Adversarial attacks have become an important area of focus in the ML community. Researchers from academia and tech companies are coming together to develop tools to protect ML models against adversarial attacks.
Earlier this year, AI researchers at 13 organizations, including Microsoft, IBM, Nvidia, and MITRE, jointly published the Adversarial ML Threat Matrix, a framework meant to help developers detect possible points of compromise in the machine learning pipeline. The ML Threat Matrix is important because it doesn’t only focus on the security of the machine learning model but on all the components that comprise your system, including servers, sensors, websites, etc.
The AI Incident Database is a crowdsourced bank of events in which machine learning systems have gone wrong. It can help you learn about the possible ways your system might fail or be exploited.
Big tech companies have also released tools to harden machine learning models against adversarial attacks. IBM’s Adversarial Robustness Toolbox is an open-source Python library that provides a set of functions to evaluate ML models against different types of attacks. Microsoft’s Counterfit is another open-source tool that checks machine learning models for adversarial vulnerabilities.
Machine learning needs new perspectives on security. We must learn to adjust our software development practices according to the emerging threats of deep learning as it becomes an increasingly important part of our applications. Hopefully, these tips will help you better understand the security considerations of machine learning. For more on the topic, see Pin-Yu Chen’s talk on adversarial robustness.
This article was originally published by Ben Dickson on TechTalks, a publication that examines trends in technology, how they affect the way we live and do business, and the problems they solve. But we also discuss the evil side of technology, the darker implications of new tech, and what we need to look out for. You can read the original article here.
Get the TNW newsletter
Get the most important tech news in your inbox each week.