Alongside cooking for myself and walking laps around the house, Japanese cartoons (or “anime” as the kids are calling it) are something I’ve learned to love during quarantine.
The problem with watching anime, though, is that short of learning Japanese, you become dependent on human translators and voice actors to port the content to your language. Sometimes you get the subtitles (“subs”) but not the voicing (“dubs”). Other times, entire seasons of shows aren’t translated at all, and you’re left on the edge of your seat with only Wikipedia summaries and 90s web forums to ferry you through the darkness.
So what are you supposed to do? The answer is obviously not to ask a computer to transcribe, translate, and voice-act entire episodes of a TV show from Japanese to English. Translation is a careful art that can’t be automated and requires the loving touch of a human hand. Besides, even if you did use machine learning to translate a video, you couldn’t use a computer to dub… I mean, who would want to listen to machine voices for an entire season? It’d be awful. Only a real sicko would want that.
So in this post, I’ll show you how to use machine learning to transcribe, translate, and voice-act videos from one language to another, i.e. “AI-Powered Video Dubs.” It might not get you Netflix-quality results, but you can use it to localize online talks and YouTube videos in a pinch. We’ll start by transcribing audio to text using Google Cloud’sSpeech-to-Text API. Next, we’ll translate that text with theTranslate API. Finally, we’ll “voice act” the translations using theText-to-Speech API, which produces voices that are, according to the docs, “humanlike.”
(By the way, before you flame-blast me in the comments, I should tell you that YouTube willautomatically and for free transcribe and translate your videos for you. So you can treat this project like your new hobby of baking sourdough from scratch: a really inefficient use of 30 hours.)
AI-dubbed videos: Do they usually sound good?
Before you embark on this journey, you probably want to know what you have to look forward to. What quality can we realistically expect to achieve from an ML-video-dubbing pipeline?
Here’s one example dubbed automatically from English to Spanish (the subtitles are also automatically generated in English). I haven’t done any tuning or adjusting on it:
As you can see, the transcriptions are decent but not perfect, and the same for the translations. (Ignore the fact that the speaker sometimes speaks too fast — more on that later.) Overall, you can easily get the gist of what’s going on from this dubbed video, but it’s not exactly near human-quality.
What makes this project trickier (read: more fun) than most is that there are at least three possible points of failure:
The video can be incorrectly transcribed from audio to text by the Speech-to-Text API
That text can be incorrectly or awkwardly translated by the Translation API
Those translations can be mispronounced by the Text-to-Speech API
In my experience, the most successful dubbed videos were those that featured a single speaker over a clear audio stream and that were dubbed from English to another language. This is largely because the quality of transcription (Speech-to-Text) was much higher in English than in other source languages.
Dubbing from non-English languages proved substantially more challenging. Here’s one particularly unimpressive dub from Japanese to English of one of my favorite shows, Death Note:
If you want to leave translation/dubbing to humans, well–I can’t blame you. But if not, read on!
Building an AI Translating Dubber
As always, you can find all of the code for this project in theMaking with Machine Learning Github repo. To run the code yourself, follow the README to configure your credentials and enable APIs. Here in this post, I’ll just walk through my findings at a high level.
First, here are the steps we’ll follow:
Extract audio from video files
Convert audio to text using the Speech-to-Text API
Split transcribed text into sentences/segments for translation
Translate text
Generate spoken audio versions of the translated text
Speed up the generated audio to align with the original speaker in the video
Stitch the new audio on top of the fold audio/video
I admit that when I first set out to build this dubber, I was full of hubris–all I had to do was plug a few APIs together, what could be easier? But as a programmer, all hubris must be punished, and boy, was I punished.
The challenging bits are the ones I bolded above, that mainly come from having to align translations with video. But more on that in a bit.
Using the Google Cloud Speech-to-Text API
The first step in translating a video is transcribing its audio to words. To do this, I used Google Cloud’sSpeech-to-Text API. This tool can recognize audio spoken in 125 languages, but as I mentioned above, the quality is highest in English. For our use case, we’ll want to enable a couple of special features, like:
Enhanced models. These are Speech-to-Text models that have been trained on specific data types (“video,” “phone_call”) and are usually higher-quality. We’ll use the “video” model, of course.
Profanity filters. This flag prevents the API from returning any naughty words.
Word time offsets. This flag tells the API that we want transcribed words returned along with the times that the speaker said them. We’ll use these timestamps to help align our subtitles and dubs with the source video.
Speech Adaption. Typically, Speech-to-Text struggles most with uncommon words or phrases. If you know certain words or phrases are likely to appear in your video (i.e. “gradient descent,” “support vector machine”), you can pass them to the API in an array that will make the more likely to be transcribed:
The API returns the transcribed text along with word-level timestamps as JSON. As an example, I transcribedthis video. You can see the JSON returned by the API in this gist. The output also lets us do a quick quality sanity check:
What I actually said:
“Software Developers. We’re not known for our rockin’ style, are we? Orarewe? Today, I’ll show you how I used ML to make me trendier, taking inspiration from influencers.”
What the API thought I said:
“Software developers. We’re not known for our Rock and style. Are we or are we today? I’ll show you how I use ml to make new trendier taking inspiration from influencers.”
In my experience, this is about the quality you can expect when transcribing high-quality English audio. Note that the punctuation is a little off. If you’re happy with viewers getting the gist of a video, this is probably good enough, although it’s easy to manually correct the transcripts yourself if you speak the source language.
At this point, we can use the API output to generate (non-translated) subtitles. In fact, if you run my script with the `–srt` flag, it will do exactly that for you (srtis a file type for closed captions):
Machine translation
Now that we have the video transcripts, we can use theTranslate API to… uh… translate them.
This is where things start to get a little ?.
Our objective is this: we want to be able to translate words in the original video and then play them back at roughly the same point in time, so that my “dubbed” voice is speaking in alignment with my actual voice.
The problem, though, is that translations aren’t word-for-word. A sentence translated from English to Japanese may have a word order jumbled. It may contain fewer words, more words, different words, or (as is the case with idioms) completely different wording.
One way we can get around this is by translating entiresentencesand then trying to align the time boundaries of those sentences. But even this becomes complicated, because how do you denote a single sentence? In English, we can split words by punctuation mark, i.e.:
But punctuation differs by language (there’s no ¿ in English), and some languages don’t separate sentences by punctuation marks at all.
Plus, in real-life speech, we often don’t talk in complete sentences. Y’know?
Another wrinkle that makes translating transcripts difficult is that, in general, themorecontext you feed into a translation model, the higher quality translation you can expect. So for example, if I translate the following sentence into French:
“I’m feeling blue, but I like pink too.”
I’ll get the translation:
“Je me sens bleu, mais j’aime aussi le rose.”
This is accurate. But if I split that sentence in two (“I’m feeling blue” and “But I like pink too”) and translate each part separately, I get:
“Je me sens triste, mais j’aime aussi le rose”, i.e. “I’m feeling sad, but I like pink too.”
This is all to say that the more we chop up text before sending it to the Translate API, the worse quality the translations will be (though it’ll be easier to temporally align them with the video).
Ultimately, the strategy I chose was to split up spoken words every time the speaker took a greater-than-one-second pause in speaking. Here’s an example of what that looked like:
This naturally led to some awkward translations (i.e. “or are we” is a weird fragment to translate), but I found it worked well enough.Here’swhere that logic looks like in code.
Side bar: I also noticed that the accuracy of the timestamps returned by the Speech-to-Text API was significantly less for non-English languages, which further decreased the quality of Non-English-to-English dubbing.
And one last thing. If you already know how you want certain words to be translated (i.e. my name, “Dale,” should always be translated simply to “Dale”), you can improve translation quality by taking advantage of the “glossary” feature of the Translation API Advanced. I wrote a blog post about thathere.
The Media Translation API
As it happens, Google Cloud is working on a new API to handle exactly the problem of translating spoken words. It’s called theMedia Translation API, and it runs translation on audio directly (i.e. no transcribed text intermediary). I wasn’t able to use that API in this project because it doesn’t yet return timestamps (the tool is currently in beta), but I think it’d be great to use in future iterations!
Text-to-Speech
Now for the fun bit–picking out computer voices! If you read about myPDF-to-Audiobook converter, you know that I love me a funny-sounding computer voice. To generate audio for dubbing, I used the Google Cloud Text-to-Speech API. The TTS API can generate lots of different voices in different languages with different accents, which you can find and play withhere. The “Standard” voices might sound a bit, er,tinny, if you know what I mean, but theWaveNet voices, which are generated by high-quality neural networks, sound decently human.
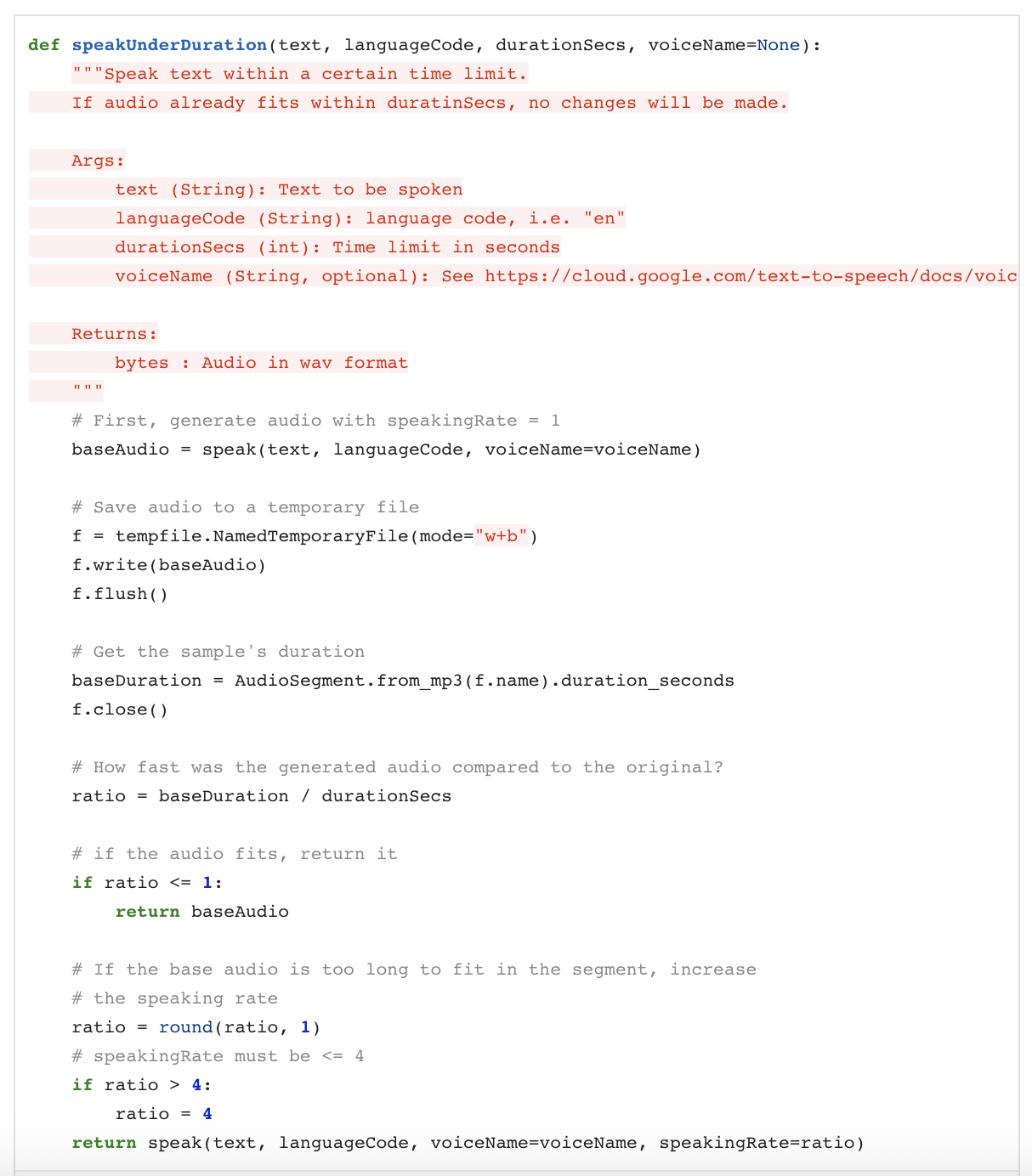
Here I ran into another problem I didn’t foresee: what if a computer voice speaks a lot slower than a video’s original speaker does, so that the generated audio file is too long? Then the dubs would be impossible to align to the source video. Or, what if a translation is more verbose than the original wording, leading to the same problem?
To deal with this issue, I played around with thespeakingRateparameter available in the Text-to-Speech API. This allows you to speed up or slow down a computer voice:
So, if it took the computer longerto speak a sentence than it did for the video’s original speaker, I increased the speakingRate until the computer and human took up about the same amount of time.
Sound a little complicated? Here’s what the code looks like:
This solved the problem of aligning audio to video, but it did sometimes mean the computer speakers in my dubs were a little awkwardly fast. Butthat’sa problem for V2.
Was it worth it?
You know the expression, “Play stupid games, win stupid prizes?” It feels like every ML project I build here is something of a labor of love, but this time, I love my stupid prize: the ability to generate an unlimited number of weird, robotic, awkward anime dubs, that are sometimes kinda decent.
Check out my results here:
This article was written by Dale Markowitz, an Applied AI Engineer at Google based in Austin, Texas, where she works on applying machine learning to new fields and industries. She also likes solving her own life problems with AI, and talks about it on YouTube.
Get the TNW newsletter
Get the most important tech news in your inbox each week.