
When I was young, I always hated being named Dale. This is mostly because my primary image of what Dales looked like was shaped by Dale Gribble from King of the Hill, and also Dale Earnhardt Jr., the NASCAR driver.
 , Dale Earnhardt Jr image [credit](https://en.wikipedia.org/wiki/File:DaleJrRVA2018.png)](https://daleonai.com/images/2020-02-06-building-a-deep-learning-powered-baby-name-generator/1.png)
Neither of these Dales fit my aspirational self-image. On the contrary, I wanted to be named Sailor Moon.
I did not like that my name was “androgynous” — 14 male Dales are born for every one female Dale. When I asked my parents about this, their rationale was:
A. Women with androgynous names are potentially more successful.
B. Their hipster friends just named their daughter Dale and it was just so cute!
To their credit, as an adult, I sure do feel I’ve benefited from pretending to be a man (or not outright denying it) on my resume, on Github, in my email signature, or even here.
[Read: Trouble with your tennis serves and penalty kicks? There’s an AI for that]
But sexism aside, what if there really is something to nominative determinism — the idea that people tend to take on jobs or lifestyles that fit their names?¹ And if your name does have some impact on the life you lead, what a responsibility it must be to choose a name for a whole human person. I wouldn’t want to leave that responsibility to taste or chance or trends. Of course not — I’d turn to deep learning (duh!).
In this post, I’ll show you how I used machine learning to build a baby name generator (or predictor, more accurately) that takes a description of a (future) human and returns a name, i.e.:
My child will be born in New Jersey. She will grow up to be a software developer at Google who likes biking and coffee runs.
Given a bio, the model will return a set of names, sorted by probability:
Name: linda Score: 0.04895663261413574
Name: kathleen Score: 0.0423438735306263
Name: suzanne Score: 0.03537878766655922
Name: catherine Score: 0.030525485053658485
...
So in theory I should’ve been a Linda, but at this point, I’m really quite attached to Dale.
If you want to try this model out yourself, take a look here. Now you definitely shouldn’t put much weight into these predictions, because a. they’re biased and b. they’re about as scientific as a horoscope. But still — wouldn’t it be cool to have the first baby named by an AI?
The dataset
Although I wanted to create a name generator, what I really ended up building was a name predictor. I figured I would find a bunch of descriptions of people (biographies), block out their names, and build a model that would predict what those (blocked out) names should be.
Happily, I found just that kind of dataset here, in a Github repo called wikipedia-biography-dataset by David Grangier. The dataset contains the first paragraph of 728,321 biographies from Wikipedia, as well as various metadata.
Naturally, there’s a selection bias when it comes to who gets a biography on Wikipedia (according to The Lily, only 15% of bios on Wikipedia are of women, and I assume the same could be said for non-white people). Plus, the names of people with biographies on Wikipedia will tend to skew older, since many more famous people were born over the past 500 years than over the past 30 years.
To account for this, and because I wanted my name generator to yield names that are popular today, I downloaded the census’s most popular baby names and cut down my Wikipedia dataset to only include people with census-popular names. I also only considered names for which I had at least 50 biographies. This left me with 764 names, majority male.
The most popular name in my dataset was “John,” which corresponded to 10092 Wikipedia bios (shocker!), followed by William, David, James, George, and the rest of the biblical-male-name docket. The least popular names (that I still had 50 examples of) were Clark, Logan, Cedric, and a couple more, with 50 counts each. To account for this massive skew, I downsampled my dataset one more time, randomly selecting 100 biographies for each name.
Training a model
Once I had my data sample, I decided to train a model that, given the text of the first paragraph of a Wikipedia biography, would predict the name of the person that bio was about.
If it’s been a while since you’ve read a Wikipedia biography, they usually start something like this:
Dale Alvin Gribble is a fictional character in the Fox animated series King of the Hill,[2] voiced by Johnny Hardwick (Stephen Root, who voices Bill, and actor Daniel Stern had both originally auditioned for the role). He is the creator of the revolutionary “Pocket Sand” defense mechanism, an exterminator, bounty hunter, owner of Daletech, chain smoker, gun fanatic, and paranoid believer of almost all conspiracy theories and urban legends.
Because I didn’t want my model to be able to “cheat,” I replaced all instances of the person’s first and last name with a blank line: “___”. So the bio above becomes:
__ Alvin __ is a fictional character in the Fox animated series…
This is the input data to my model, and its corresponding output label is “Dale.”
Once I prepared my dataset, I set out to build a deep learning language model. There were lots of different ways I could have done this (here’s one example in Tensorflow), but I opted to use AutoML Natural Language, a code-free way to build deep neural networks that analyze text.
I uploaded my dataset into AutoML, which automatically split it into 36,497 training examples, 4,570 validation examples, a 4,570 test examples:
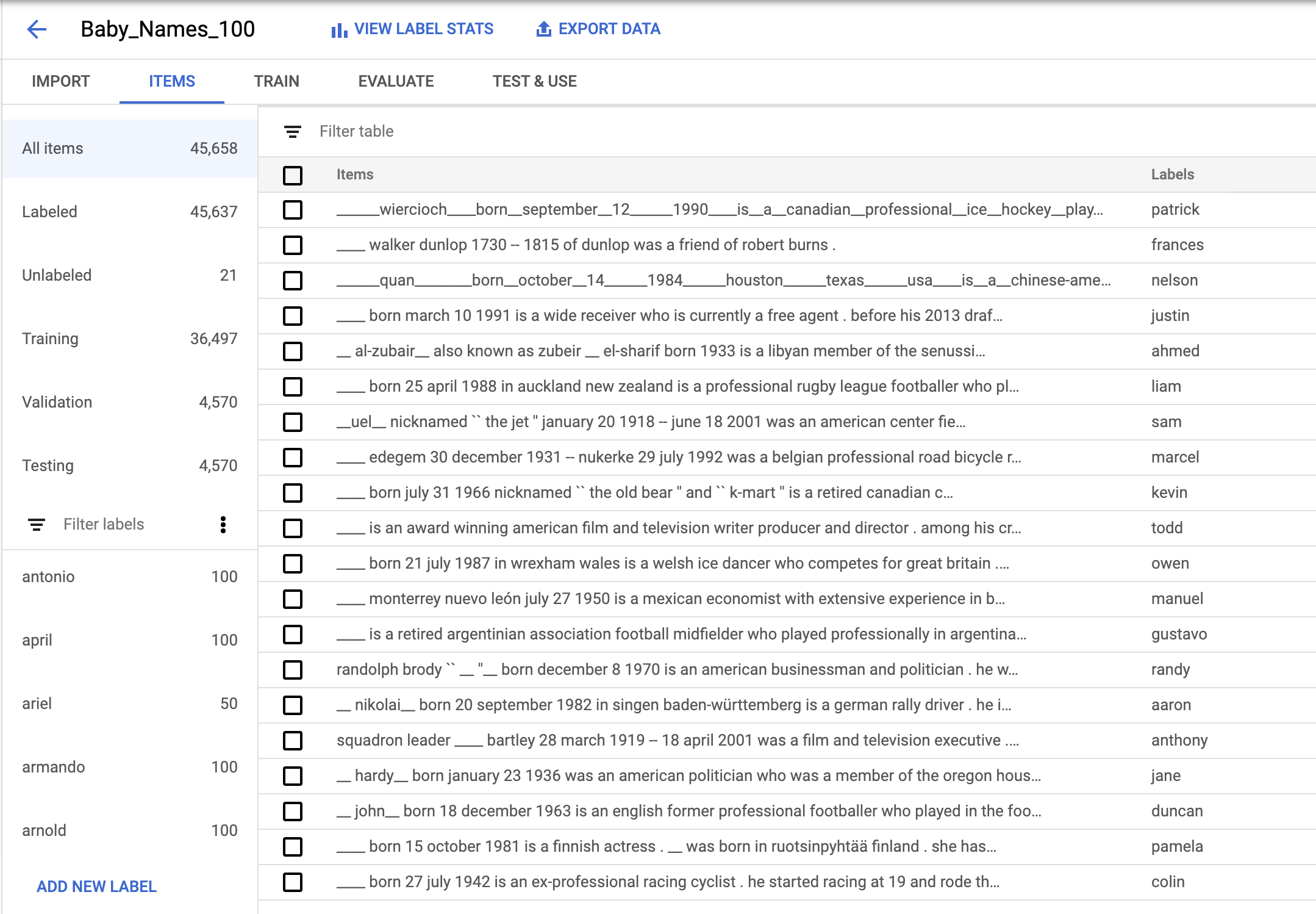
To train a model, I navigated to the “Train” tab and clicked “Start Training.” Around four hours later, training was done.
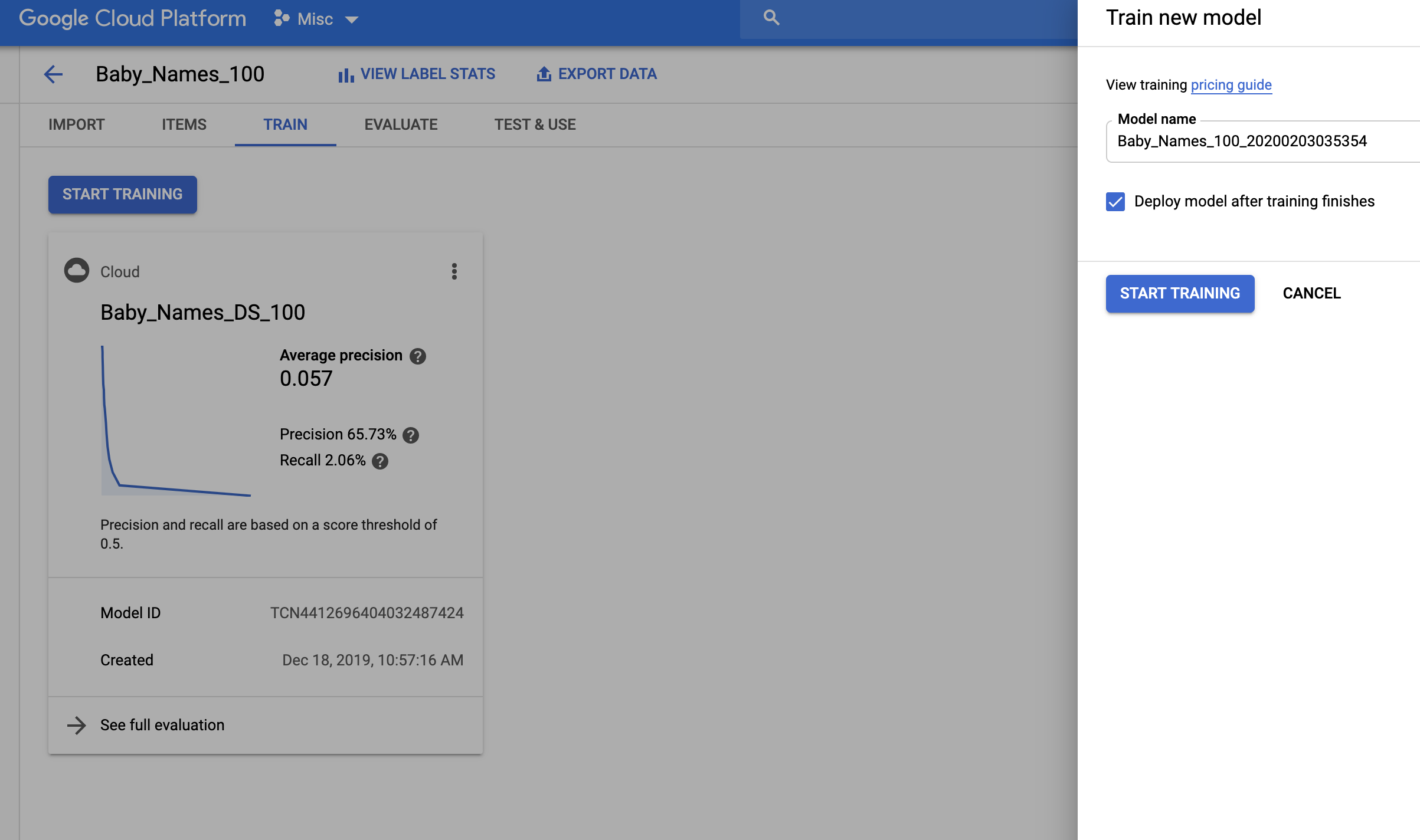
So how well did the name generator model do?
If you’ve built models before, you know the go-to metrics for evaluating quality are usually precision and recall (if you’re not familiar with these terms or need a refresher, check out this nice interactive demo my colleague Zack Akil built to explain them!). In this case, my model had a precision of 65.7% and a recall of 2%.
But in the case of our name generator model, these metrics aren’t really that telling. Because the data is very noisy — there is no “right answer” to what a person should be named based on his or her life story. Names are largely arbitrary, which means no model can make really excellent predictions.
My goal was not to build a model that with 100% accuracy could predict a person’s name. I just wanted to build a model that understood something about names and how they work.
One way to dig deeper into what a model’s learned is to look at a table called a confusion matrix, which indicates what types of errors a model makes. It’s a useful way to debug or do a quick sanity check.
In the “Evaluate” tab, AutoML provides a confusion matrix. Here’s a tiny corner of it (cut off because I had sooo many names in the dataset):
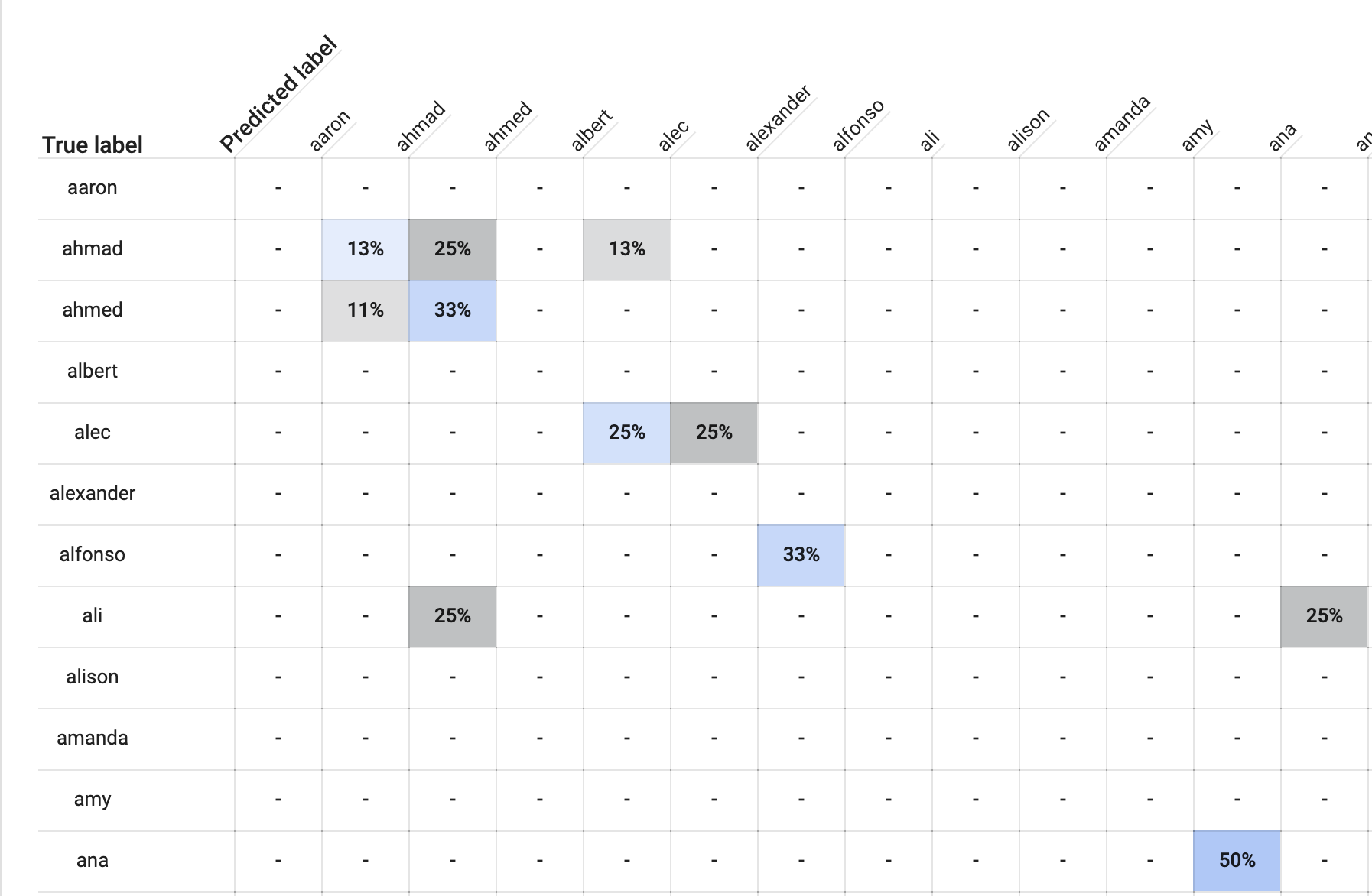
So for example, take a look at the row labeled “ahmad.” You’ll see a light blue box labeled “13%”. This means that, of all the bios of people named Ahmad in our dataset, 13% were labeled “ahmad” by the model. Meanwhile, looking one box over to the right, 25% of bios of peopled named “ahmad” were (incorrectly) labeled “ahmed.” Another 13% of people named Ahmad were incorrectly labeled “alec.”
Although these are technically incorrect labels, they tell me that the model has probably learned something about naming, because “ahmed” is very close to “ahmad.” Same thing for people named Alec. The model labeled Alecs as “alexander” 25% of the time, but by my read, “alec” and “alexander” are awfully close names.
Running sanity checks
Next, I decided to see if my model understood basic statistical rules about naming. For example, if I described someone as a “she,” would the model predict a female name, versus a male name for “he”?
For the sentence “She likes to eat,” the top predicted names were “Frances,” “Dorothy,” and “Nina,” followed by a handful of other female names. Seems like a good sign.
For the sentence “He likes to eat,” the top names were “Gilbert,” “Eugene,” and “Elmer.” So it seems the model understands some concept of gender.
Next, I thought I’d test whether it was able to understand how geography played into names. Here are some sentences I tested and the model’s predictions:
“He was born in New Jersey” — Gilbert
“She was born in New Jersey” — Frances
“He was born in Mexico.” — Armando
“She was born in Mexico” — Irene
“He was born in France.” — Gilbert
“She was born in France.” — Edith
“He was born in Japan” — Gilbert
“She was born in Japan” — Frances
I was pretty unimpressed with the model’s ability to understand regionally popular names. The model seemed especially bad at understanding what names are popular in Asian countries, and tended in those cases just to return the same small set of names (i.e. Gilbert, Frances). This tells me I didn’t have enough global variety in my training dataset.
Model bias
Finally, I thought I’d test for one last thing. If you’ve read at all about Model Fairness, you might have heard that it’s easy to accidentally build a biased, racist, sexist, agest, etc. model, especially if your training dataset isn’t reflective of the population you’re building that model for. I mentioned before there’s a skew in who gets a biography on Wikipedia, so I already expected to have more men than women in my dataset.
I also expected that this model, reflecting the data it was trained on, would have learned gender bias — that computer programmers are male and nurses are female. Let’s see if I’m right:
“They will be a computer programmer.” — Joseph
“They will be a nurse.” — Frances
“They will be a doctor.” — Albert
“They will be an astronaut.” — Raymond
“They will be a novelist.” — Robert
“They will be a parent.” — Jose
“They will be a model.” — Betty
Well, it seems the model did learn traditional gender roles when it comes to profession, the only surprise (to me, at least) that “parent” was predicted to have a male name (“Jose”) rather than a female one.
So evidently this model has learned something about the way people are named, but not exactly what I’d hoped it would. Guess I’m back to square one when it comes to choosing a name for my future progeny…Dale Jr.?
This article was written by Dale Markowitz, an Applied AI Engineer at Google based in Austin, Texas, where she works on applying machine learning to new fields and industries. She also likes solving her own life problems with AI, and talks about it on YouTube.
Get the TNW newsletter
Get the most important tech news in your inbox each week.