
Don McClean has always had to share “American Pie.” Since its release in 1971, the hit song has re-emerged in covers by Madonna, parodies by Weird Al Yankovic, serenades by South Korean presidents, subplots in Marvel movies, and even CIA torture techniques. But these days, McClean’s leading imitators aren’t even human.
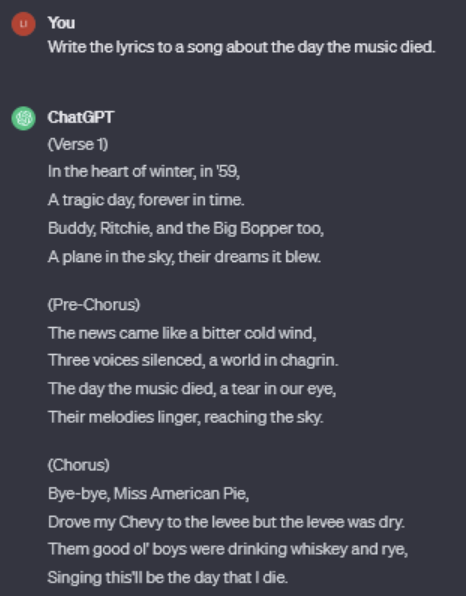
You can interrogate the culprits for yourself. Just load OpenAI’s ChatGPT and prompt the text generator to “write the lyrics to a song about the day the music died.” Invariably, the tool’s output will spit out lyrics or themes from “American Pie” — and sometimes the same chorus.
This regurgitation emerges despite the prompt making no order for “American Pie” or the story that inspired it — the 1959 plane crash that killed rock and roll pioneers Buddy Holly, Ritchie Valens, and The Big Bopper.
It’s further evidence that ChatGPT can’t create anything truly original. Instead, the system is closer to a remix algorithm. The real creativity is in its training data, which is scraped from the web without consent.
Dr Max Little, an AI expert at the University of Birmingham, describes the tool as an “infringement machine.” He scoffs at any suggestion that large language models (LLM) are independently creative.

The 💜 of EU tech
The latest rumblings from the EU tech scene, a story from our wise ol' founder Boris, and some questionable AI art. It's free, every week, in your inbox. Sign up now!
“This is not the case because they cannot produce anything at all without being trained on astronomical amounts of text,” Little tells TNW.
It’s an approach that’s ubiquitous in generative AI. Rigorous studies have shown that LLMs can regurgitate large chunks of their original training text, including verbatim paragraphs from books and poems. Just last week, a report found that 60% of OpenAI’s GPT-3.5 outputs contained plagiarism.
Nor does the issue solely apply to text generators. From Stable Diffusion’s images to Google Lyria’s music and GitHub Copilot’s code, GenAI tools across modalities can produce outputs of gobsmacking quality — and eerie familiarity.
Their mimicry poses an existential threat to creative industries. It also poses a threat to the GenAI industry.
Fair training
Artists say that GenAI’s relentless march is trampling over their copyright conventions. Unsurprisingly, tech companies disagree. Their defences typically invoke the “fair use” doctrine.
Details vary by jurisdiction, but a central tenet of “fair use” is that the outputs have a “transformative” purpose and character. Rather than merely copying or reproducing their training data, they add something new and significant. At least, that’s what the GenAI leaders are contending in court.
Stability AI, the UK-based startup behind the image-generator Stable Diffusion, made that argument last year to the US Copyright Office. OpenAI also cited the doctrine in a recent motion to dismiss two class-action lawsuits.
Several authors, including comedian Sarah Silverman and Canadian novelist Mona Awad, had sued the company for allegedly training LLMs on illegally acquired datasets.
Because their work was baked into ChatGPT, they said the tool itself was a “derivative work” covered by copyright.
OpenAI rebuffed the claim. According to the startup’s legal team, “the use of copyrighted materials by innovators in transformative ways does not violate copyright.” A judge also dismissed the allegation that every ChatGPT output is derivative.
But when the outputs are identical to their training data, the legal waters start to muddy. Reproduction is a dubious basis for transformation. It’s also a common phenomenon.
As well as American pies, GenAI tools have regurgitated film scenes, cartoon characters, video games, product designs, and code.
They’ve also copied newspapers — which may lead to a tipping point.
“Transformative nature”, my eye, @OpenAI.@Disney ain’t gonna see it that way. https://t.co/t0A0lfM6f9 pic.twitter.com/0XX51yQjN2
— Gary Marcus @ AAAI 2024 (@GaryMarcus) December 29, 2023
Legal copies
In December, the New York Times sued OpenAI and its business partner Microsoft. The news outlet alleges the unauthorised use of its articles in training data breaches intellectual property (IP) rights. Legal experts describe the suit as “the best case yet alleging that generative AI is copyright infringement.”
Lawyers for the NYT highlighted the “substantial similarity” between the outlet’s content and ChatGPT outputs. To substantiate the claim, they provided 100 examples of the bot reproducing the newspaper’s reporting.
“In each case, we observe that the output of GPT-4 contains large spans that are identical to the actual text of the article from The New York Times,” they said in their complaint.
Their suit also challenges another key aspect of “fair use”: the impact on the market for the original work.

According to the plaintiffs, OpenAI not only replicates NYT content, but also exploits the content to compete in the same markets. At the same time, the company diverts traffic away from the newspaper’s website.
As evidence, they point to Browse with Bing, a premium feature powered by the same tech behind ChatGPT. The tool can summarise product recommendations made by NYT reviewers. By offering users this information, the lawyers said, OpenAI removes their incentive to visit the original article. This also means they don’t click on the product links that generate revenues for the publisher.
“There is nothing ‘transformative’ about using The Times’s content without payment to create products that substitute for The Times and steal audiences away from it,” the complaint declared.
Naturally, the GenAI giants disagree.
Creative conflict
OpenAI responded to the lawsuit in a reproachful blogpost. The company suspects that the NYT either “instructed the model to regurgitate” or “cherry-picked their examples from many attempts.”
Industry insiders have concurred. Daniel Jeffries, Stability AI’s chief intelligence officer, described the prompts in the lawsuit as “obviously manipulated.” He said the copies were “almost certainly” produced via a technique called retrieval augmented generation (RAG), which optimises LLM outputs by accessing external sources of information.
“They risk destroying creative industries that depend on copyright.
Whatever the method, OpenAI said regurgitation is a “rare bug” that the company was “working to drive to zero.” But critics question the powers of preventive mechanisms.
Little points to ChatGPT’s reproduction of “American Pie.”
“Sometimes direct verbatim copyright infringement… is detected by the algorithm and a warning is presented,” he says.
“Nonetheless, the algorithm can still easily be made to produce output which is clearly plagiarised from the training data, as in this case, the theme of the lyrics is always the Holly/Valens/Bopper 1959 crash event.”
GenAI indigestion
Rare as it may be in ChatGPT, regurgitation is widespread in GenAI tools. When they demonstrably duplicate their training data and then compete in the same market, the foundations of fair use appear shaky.
Ben Maling, managing associate at intellectual property law firm EIP, is keeping a close eye on the instability. Outputs that are verbatim copies or derivatives of their training data threaten “another potential copyright infringement,” he warns. Either the system or the end user could be liable for damages.
“Many of the big AI providers are so worried about the potential of this to scare away customers that they are offering [assurances] promising to defend them against infringement actions,” Maling told TNW via email.
That’s not the only evidence of worrying at OpenAI. Last month, the GenAI flagbearer told the British Parliament that it’s “impossible” to create AI tools like ChatGPT without copyrighted material. Searching for legal protection, the company requested a special exemption for the practice.
The request elevated the fears around regurgitated training data.
If politicians exempted OpenAI, the startup “would be free to copy and remix any and all original text from anywhere and at any time,” Little says. As a result, they risk “destroying the creative industries which depend upon copyright to even exist.”
Curing regurgitation
GenAI’s regurgitation isn’t necessarily terminal. Analysts have prescribed numerous treatments for the awkward affliction.
One was created by Ed Newton-Rex, the former vice president of audio at Stability AI. During his stint at the startup, Newton-Rex developed Stable Audio, a music generator trained on licensed content. The 36-year-old wants other companies to follow his lead.
“You may slow down the AI industry a bit, because they’d have to go and spend more time, more money, and more effort on licensing,” Newton-Rex tells TNW. “But in the process, frankly, you would save the creative industries. I think there’s an existential threat here.”
Artists who face this threat have applied a more extreme antidote: poison.
The most popular delivery method is a tool called Nightshade. This software “poisons” training data by applying invisible changes to images. When companies scrape the creations without consent, they can disrupt the AI model’s outputs.
The method has proven popular. Within five days of going live, Nightshade surpassed 250,000 downloads.
Nonetheless, Little expects AI to continue regurgitating American Pies. He doubts that tools trained on scraped creative content can ever escape the plagiarism problem. “Because by design,” he says, “they are just algorithms which remix their training data.”
One of the themes of this year’s TNW Conference is Ren-AI-ssance: The AI-Powered Rebirth. If you want to go deeper into all things artificial intelligence, or simply experience the event (and say hi to our editorial team), we’ve got something special for our loyal readers. Use the code TNWXMEDIA at checkout to get 30% off your business pass, investor pass or startup packages (Bootstrap & Scaleup).
Get the TNW newsletter
Get the most important tech news in your inbox each week.