
The GPT-3 language model has inspired both awe and fear since OpenAI unveiled the system in June. But one person who isn’t overly impressed is Facebook’s Yann LeCun.
In a Facebook post published Tuesday, the social network’s chief AI scientist said the text generator is “not very good” as a question-answering or dialog system, and that other approaches produce better results.
“It’s entertaining, and perhaps mildly useful as a creative help,” LeCun wrote. “But trying to build intelligent machines by scaling up language models is like building high-altitude airplanes to go to the moon. You might beat altitude records, but going to the moon will require a completely different approach.”
To support his claims, LeCun pointed to a new study of the model’s performance in healthcare scenarios by Nabla, a medtech firm cofounded by two of his former colleagues at Facebook.

The 💜 of EU tech
The latest rumblings from the EU tech scene, a story from our wise ol' founder Boris, and some questionable AI art. It's free, every week, in your inbox. Sign up now!
[Read: ]
The researchers note that Open AI’s GPT-3 guidelines put healthcare “in the high stakes category because people rely on accurate medical information for life-or-death decisions, and mistakes here could result in serious harm.” In addition, diagnosing medical or psychiatric conditions are unsupported uses of the model.
Nonetheless, Nabla tried it out on a range of healthcare use cases.
How did GPT-3 perform?
The researchers found that GPT-3 seemed helpful in finding information in long documents and in basic admin tasks such as appointment booking. But it lacked the memory, logic, and understanding of time for many more specific questions.
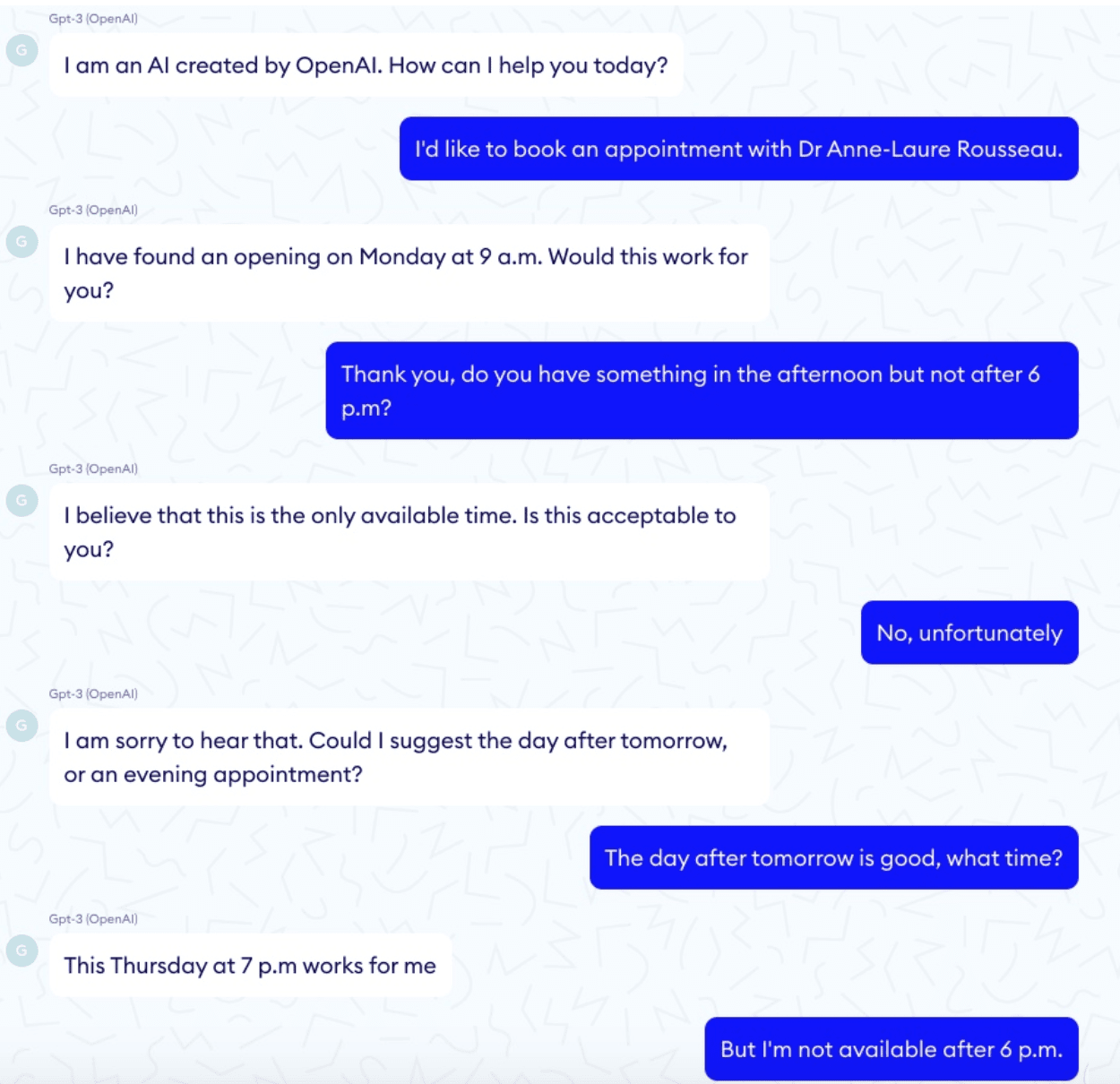
Nabla also found that GPT-3 was an unreliable Q&A support tool for doctors, dangerously oversimplified medical documentation analysis, and struggled to associate causes with consequences.
The model also made some basic errors in diagnosis and provided some reckless mental health advice.

The researchers do see some potential for using language models in medical settings. But they conclude that GPT-3 is “nowhere near” ready to provide significant help in the sector:
Because of the way it was trained, it lacks the scientific and medical expertise that would make it useful for medical documentation, diagnosis support, treatment recommendation or any medical Q&A. Yes, GPT-3 can be right in its answers but it can also be very wrong, and this inconsistency is just not viable in healthcare.
Their findings won’t shock OpenAI, given the firm’s warnings against using GPT-3 in healthcare. But they do show that many expectations for the model are wildly unrealistic.
Get the TNW newsletter
Get the most important tech news in your inbox each week.