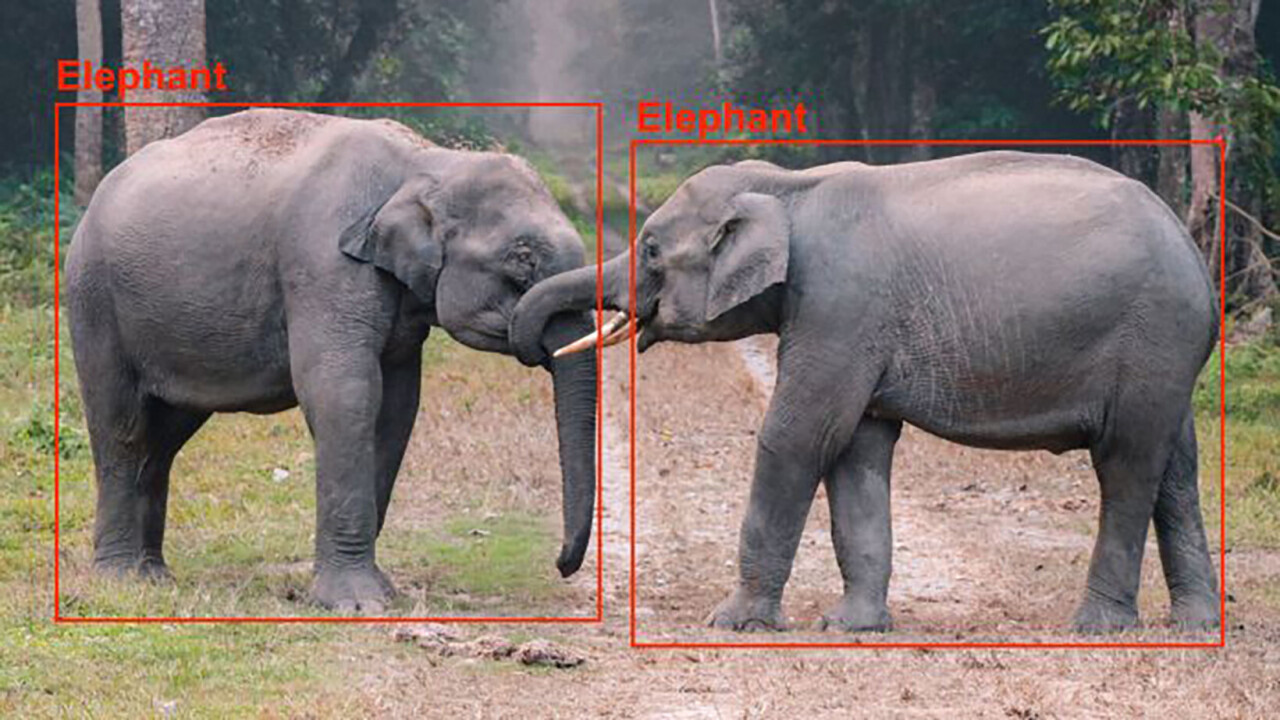
Deep neural networks have gained fame for their capability to process visual information. And in the past few years, they have become a key component of many computer vision applications.
Among the key problems neural networks can solve is detecting and localizing objects in images. Object detection is used in many different domains, including autonomous driving, video surveillance, and healthcare.
In this post, I will briefly review the deep learning architectures that help computers detect objects.
Convolutional neural networks
One of the key components of most deep learning–based computer vision applications is the convolutional neural network (CNN). Invented in the 1980s by deep learning pioneer Yann LeCun, CNNs are a type of neural network that is efficient at capturing patterns in multidimensional spaces. This makes CNNs especially good for images, though they are used to process other types of data too. (To focus on visual data, we’ll consider our convolutional neural networks to be two-dimensional in this article.)
Every convolutional neural network is composed of one or several convolutional layers, a software component that extracts meaningful values from the input image. And every convolution layer is composed of several filters, square matrices that slide across the image and register the weighted sum of pixel values at different locations. Each filter has different values and extracts different features from the input image. The output of a convolution layer is a set of “feature maps.”
When stacked on top of each other, convolutional layers can detect a hierarchy of visual patterns. For instance, the lower layers will produce feature maps for vertical and horizontal edges, corners, and other simple patterns. The next layers can detect more complex patterns such as grids and circles. As you move deeper into the network, the layers will detect complicated objects such as cars, houses, trees, and people.

Most convolutional neural networks use pooling layers to gradually reduce the size of their feature maps and keep the most prominent parts. Max-pooling, which is currently the main type of pooling layer used in CNNs, keeps the maximum value in a patch of pixels. For example, if you use a pooling layer with a size 2, it will take 2×2-pixel patches from the feature maps produced by the preceding layer and keep the highest value. This operation halves the size of the maps and keeps the most relevant features. Pooling layers enable CNNs to generalize their capabilities and be less sensitive to the displacement of objects across images.
Finally, the output of the convolution layers is flattened into a single dimension matrix that is the numerical representation of the features contained in the image. That matrix is then fed into a series of “fully connected” layers of artificial neurons that map the features to the kind of output expected from the network.
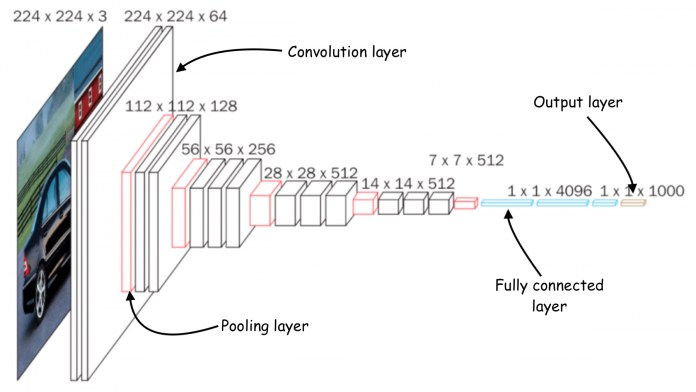
The most basic task for convolutional neural networks is image classification, in which the network takes an image as input and returns a list of values that represent the probability that the image belongs to one of several classes.
For example, say you want to train a neural network to detect all 1,000 classes of objects contained in the popular open-source dataset ImageNet. In that case, your output layer will have 1,000 numerical outputs, each of which contains the probability of the image belonging to one of those classes.
You can always create and test your own convolutional neural network from scratch. But most machine learning researchers and developers use one of several tried and tested convolutional neural networks such as AlexNet, VGG16, and ResNet-50.
Object detection datasets
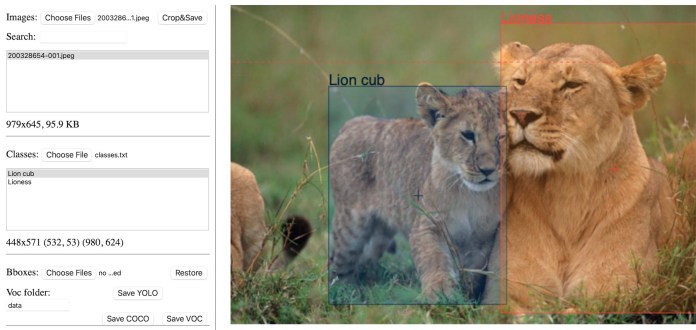
While an image classification network can tell whether an image contains a certain object or not, it won’t say where in the image the object is located. Object detection networks provide both the class of objects contained in an image and a bounding box that provides the coordinates of that object.
Object detection networks bear much resemblance to image classification networks and use convolution layers to detect visual features. In fact, most object detection networks use an image classification CNN and repurpose it for object detection.
Object detection is a supervised machine learning problem, which means you must train your models on labeled examples. Each image in the training dataset must be accompanied with a file that includes the boundaries and classes of the objects it contains. There are several open-source tools that create object detection annotations.
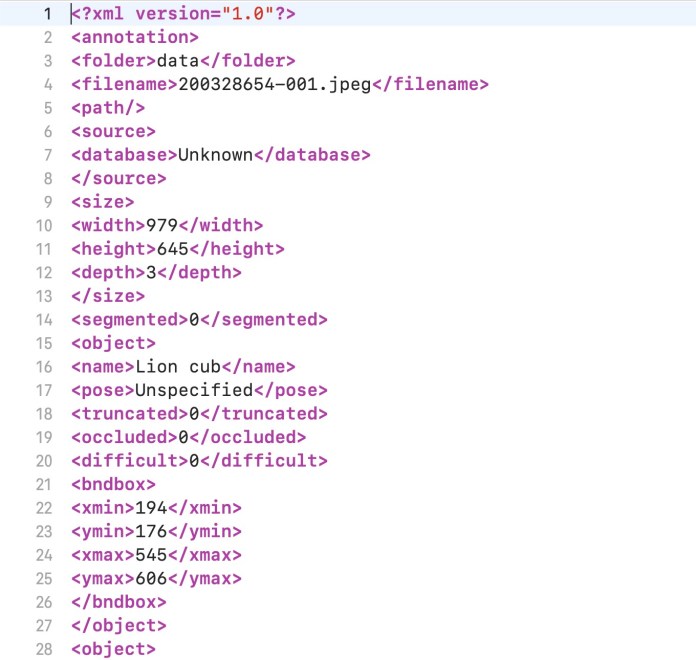
The object detection network is trained on the annotated data until it can find regions in images that correspond to each kind of object.
Now let’s look at a few object-detection neural network architectures.
The R-CNN deep learning model
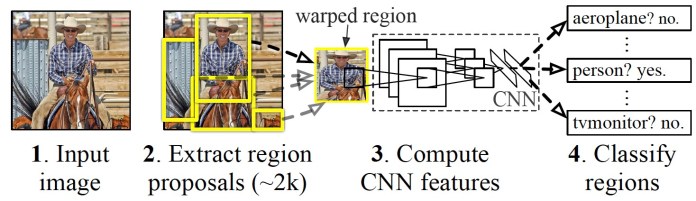
The Region-based Convolutional Neural Network (R-CNN) was proposed by AI researchers at the University of California, Berkley, in 2014. The R-CNN is composed of three key components.
First, a region selector uses “selective search,” algorithm that find regions of pixels in the image that might represent objects, also called “regions of interest” (RoI). The region selector generates around 2,000 regions of interest for each image.
Next, the RoIs are warped into a predefined size and passed on to a convolutional neural network. The CNN processes every region separately extracts the features through a series of convolution operations. The CNN uses fully connected layers to encode the feature maps into a single-dimensional vector of numerical values.
Finally, a classifier machine learning model maps the encoded features obtained from the CNN to the output classes. The classifier has a separate output class for “background,” which corresponds to anything that isn’t an object.

The original R-CNN paper suggests the AlexNet convolutional neural network for feature extraction and a support vector machine (SVM) for classification. But in the years since the paper was published, researchers have used newer network architectures and classification models to improve the performance of R-CNN.
R-CNN suffers from a few problems. First, the model must generate and crop 2,000 separate regions for each image, which can take quite a while. Second, the model must compute the features for each of the 2,000 regions separately. This amounts to a lot of calculations and slows down the process, making R-CNN unsuitable for real-time object detection. And finally, the model is composed of three separate components, which makes it hard to integrate computations and improve speed.
Fast R-CNN
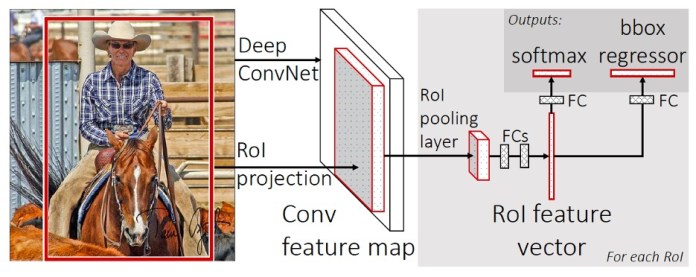
In 2015, the lead author of the R-CNN paper proposed a new architecture called Fast R-CNN, which solved some of the problems of its predecessor. Fast R-CNN brings feature extraction and region selection into a single machine learning model.
Fast R-CNN receives an image and a set of RoIs and returns a list of bounding boxes and classes of the objects detected in the image.
One of the key innovations in Fast R-CNN was the “RoI pooling layer,” an operation that takes CNN feature maps and regions of interest for an image and provides the corresponding features for each region. This allowed Fast R-CNN to extract features for all the regions of interest in the image in a single pass as opposed to R-CNN, which processed each region separately. This resulted in a significant boost in speed.
However, one issue remained unsolved. Fast R-CNN still required the regions of the image to be extracted and provided as input to the model. Fast R-CNN was still not ready for real-time object detection.
Faster R-CNN
[faster r-cnn architecture]
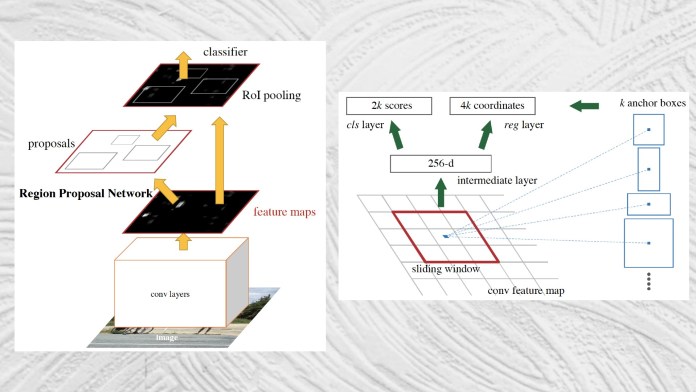
Faster R-CNN, introduced in 2016, solves the final piece of the object-detection puzzle by integrating the region extraction mechanism into the object detection network.
Faster R-CNN takes an image as input and returns a list of object classes and their corresponding bounding boxes.
The architecture of Faster R-CNN is largely similar to that of Fast R-CNN. Its main innovation is the “region proposal network” (RPN), a component that takes the feature maps produced by a convolutional neural network and proposes a set of bounding boxes where objects might be located. The proposed regions are then passed to the RoI pooling layer. The rest of the process is similar to Fast R-CNN.
By integrating region detection into the main neural network architecture, Faster R-CNN achieves near-real-time object detection speed.
YOLO
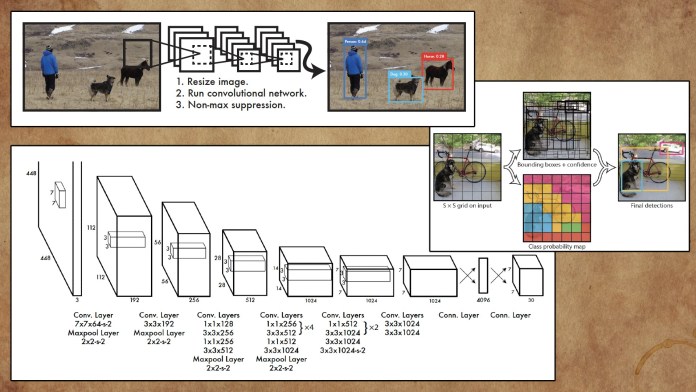
In 2016, researchers at Washington University, Allen Institute for AI, and Facebook AI Research proposed “You Only Look Once” (YOLO), a family of neural networks that improved the speed and accuracy of object detection with deep learning.
The main improvement in YOLO is the integration of the entire object detection and classification process in a single network. Instead of extracting features and regions separately, YOLO performs everything in a single pass through a single network, hence the name “You Only Look Once.”
YOLO can perform object detection at video streaming frame rates and is suitable applications that require real-time inference.
In the past few years, deep learning object detection has come a long way, evolving from a patchwork of different components to a single neural network that works efficiently. Today, many applications use object-detection networks as one of their main components. It’s in your phone, computer, car, camera, and more. It will be interesting (and perhaps creepy) to see what can be achieved with increasingly advanced neural networks.
This article was originally published by Ben Dickson on TechTalks, a publication that examines trends in technology, how they affect the way we live and do business, and the problems they solve. But we also discuss the evil side of technology, the darker implications of new tech, and what we need to look out for. You can read the original article here.
Get the TNW newsletter
Get the most important tech news in your inbox each week.